

I'm a college freshman trying to understand more about JINA AI through an event hosted by Featureprenuer. Here I'll update my daily progress on the challenge. I also use Learning Analytics to track the articles I read during this learning session
Table of Contents :-
DAY 0
Orientation -23/10
Through Zoom meetings I was introduced to the challenge and it's goals by Raja Sir and the Featureprenuer Team. Time spent : 1hr
DAY 1
Introduction - 24/10
I learned so many new things from how a neural search works and about a cool game called Serkinti by Featureprenuer. Through zoom discussions and a quick readthrough of the JINA AI documentation , I was able to understand a bit about the working of the framework. Time spent : 1.5 hrs
DAY 2
Installation - 25/10
The Installation process of JINA AI has been documented in this video.
I used a conda environment to run the demo. I have listed all the articles I read for this process in my Learning Analytics page
Time spent : 1.5 hrs
DAY 3
Testing Demo Project and Selenium - 26/10
- Forked fashion app - jina ai and tried to understand about it .I had to read the documentation again to know more about Document, Flow and Executors, the building blocks of jina.ai
This was the time i started questioning why we need neural search and I found great articles to know more about it.
What’s the deal with Neural Architecture Search? -By Liam Li, Ameet Talwalkar
Bhaskar Mitra and Nick Craswell (2018), “An Introduction to Neural Information Retrieval”
- worked on a basic selenium web scraping tool to scrape data from amazon and write the products as a csv file . try it here.
I got so much of help from the Featurepreneur team on starting with selenium. They have a great repo to get started with :
Time spent : 2.5 hrs
DAY 4
Creating own dataset and demo project - 27/10
Tried to replicate a demo project from featurepreneur courses and from Alex CG's example :
but was faced with errors due to lack of understanding the codebase. Day 4 was basically trial and error . Asked for help in slack and was able to fix it. Continued in Day 5
Time spent : 3 hrs
DAY 5
Demo project with large data - 28/10
Dataset used : windows-store.csv
from jina import Flow, Executor , requests , Document, DocumentArray
import pandas as pd
import numpy as np
df=pd.read_csv('windows_store.csv')
df= df.drop_duplicates().dropna()
# df.iloc[0]
Document(text ="text")
Document(content ="content")
Document(uri = "path" )
docs = DocumentArray()
for ind in range(df.shape[0]):
name = df.iloc[ind,0]
desc = df.iloc[ind,2]
# print(name,"-",desc,"\n")
doc = Document(text=name)
doc.tags['description'] = desc
docs.append(doc)
flow = (
Flow()
.add(uses='jinahub://SpacyTextEncoder')
.add(uses='jinahub://SimpleIndexer')
# .add().plot('f.svg')
)
with flow:
flow.index(inputs=docs)
query = Document(text=input("App Name:"))
response = flow.search(inputs=query, return_results=True)
matches = response[0].data.docs[0].matches
print("Your search results")
print("-------------------\n")
i=0
for match in matches:
i+=1
if(i==1):
print("Closest Match for",match.text,"Description : ", match.tags.fields['description'].string_value,"\n")
else:
print("Similar Query",i)
print("-------------------\n")
print(match.tags.fields['description'].string_value)
Time spent : 2.5 hrs
DAY 6
Learning about Streamlit,jinabox and data in jina - 29/10
Spent day 6 learning about streamlit-jina : an easy way to integrate jina to frontend using streamlit library , which is a tool that makes python apps run on the web. It also helps in an easier deploying of the product to the cloud.
jinabox : a js component that works along with jina backend to query and display results from the backend.
DataTypes in jina :
jina offers indexing and querying of text,image,video,audio and 3d mesh . My specific field of interest was in image querying since text querying was understood through the demo projects. To query an image in jina we need to convert it into a blob , as an ndarray . I tried out the basic example in jina on converting image of an apple into a blob and converted the blob back into a png file. This made me learn more about numpy and ndarrays and about image processing and image embedding
Time spent : 2 hrs
DAY 7
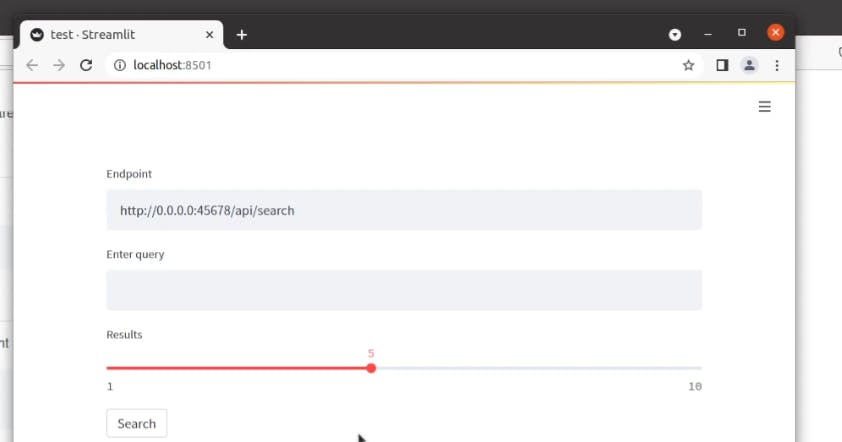
Installing streamlit-jina and running demo - 30/10
1 : Install via terminal
pip install streamlit-jina
import streamlit as st
from streamlit_jina import jina
st.set_page_config(page_title="Jina Text Search",)
endpoint = "http://0.0.0.0:45678/api/search"
st.title("Jina Text Search")
st.markdown("You can run our [Wikipedia search example](https://github.com/jina-ai/examples/tree/master/wikipedia-sentences) to test out this search")
jina.text_search(endpoint=endpoint)
Time spent : 2 hrs
DAY 8
Socialising and finding kaggle datasets - 31/10
I spent DAY 8 connecting with my fellow participants and getting to know them more. It was a fun event. The next part of DAY 8 was finding some cool kaggle datasets to work on my project. Searching for new datasets would help me get a clearer idea on what project i would like to work on.
Time spent : 3 hrs